Yosafat

Experienced Data Scientist with a strong background in programming, development and deployment of ML/DL models, and data analytics. Possessing 2 years of hands-on experience in the data field, encompassing end-to-end ML/DL model development, Natural Language Processing (NLP) implementation, ML/DL framework utilization, data analysis, and web scraping. Proficient in Python, ML/DL frameworks such as PyTorch, TensorFlow, Keras, and scikit-learn, and experienced using cloud platforms such as Amazon Web Services and Google Cloud Platform. Interested in and familiar with LLM implementation including Transfer Learning, RAG, and Multimodal AI. Demonstrated ability to collaborate effectively in teams and work independently, with strong analytical skills to solve complex problems.
Portfolio
1. Large Language Models (LLMs)
1.1. IndoBERT Sentiment Analysis: Sentiment Analysis with IndoBERT Fine-tuning and IndoNLU SmSA Dataset

This project contains the end-to-end development of LLM text classification model by fine-tuning pre-trained IndoBERT model using IndoNLU SmSA dataset. This model is able to predict sentence sentiment into several categories namely positive, neutral, and negative.
1.2. Text Summarization using LangChain and BART Large CNN

This project features the development and implementation of an advanced text summarization system using LangChain and BART-Large-CNN. This project allows users to summarize long text entered in the app into a few sentences.
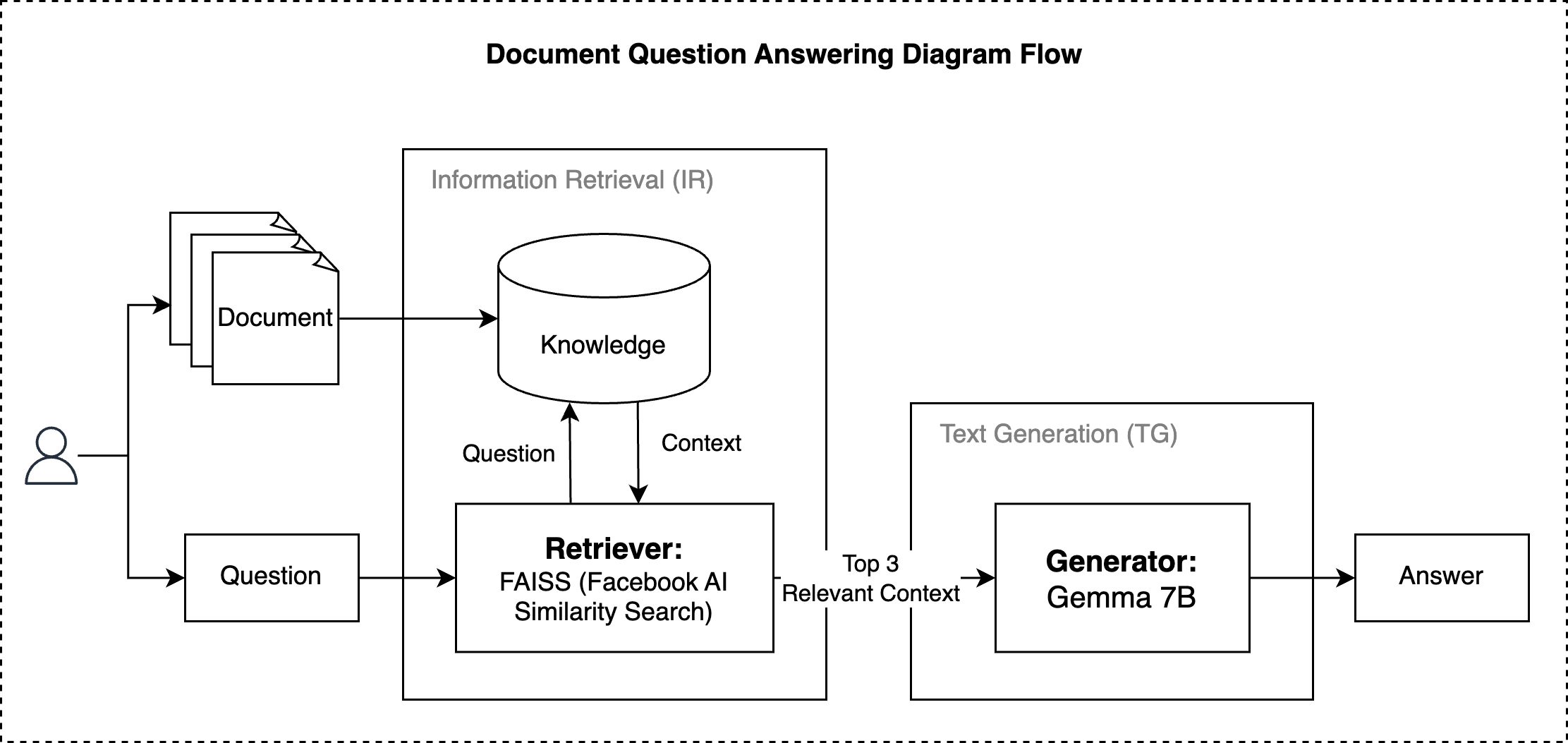
1.3. Document Question Answering using LangChain, F.A.I.S.S., and Gemma

This project features the integration and implementation of an advanced document question answering system using LangChain, FAISS (Facebook AI Similarity Search), and Gemma 7b. This system can answer questions asked by users from documents that have been uploaded. Furthermore, this project applies Retrieval-Augmented Generation (RAG) technique to optimize LLM with external knowledge to improve the output. The RAG technique approach applied in this project is Retriever-Generator, Retriever works to retrieve relevant information (context), then Generator works to generate answers from the context.
2. Machine Learning
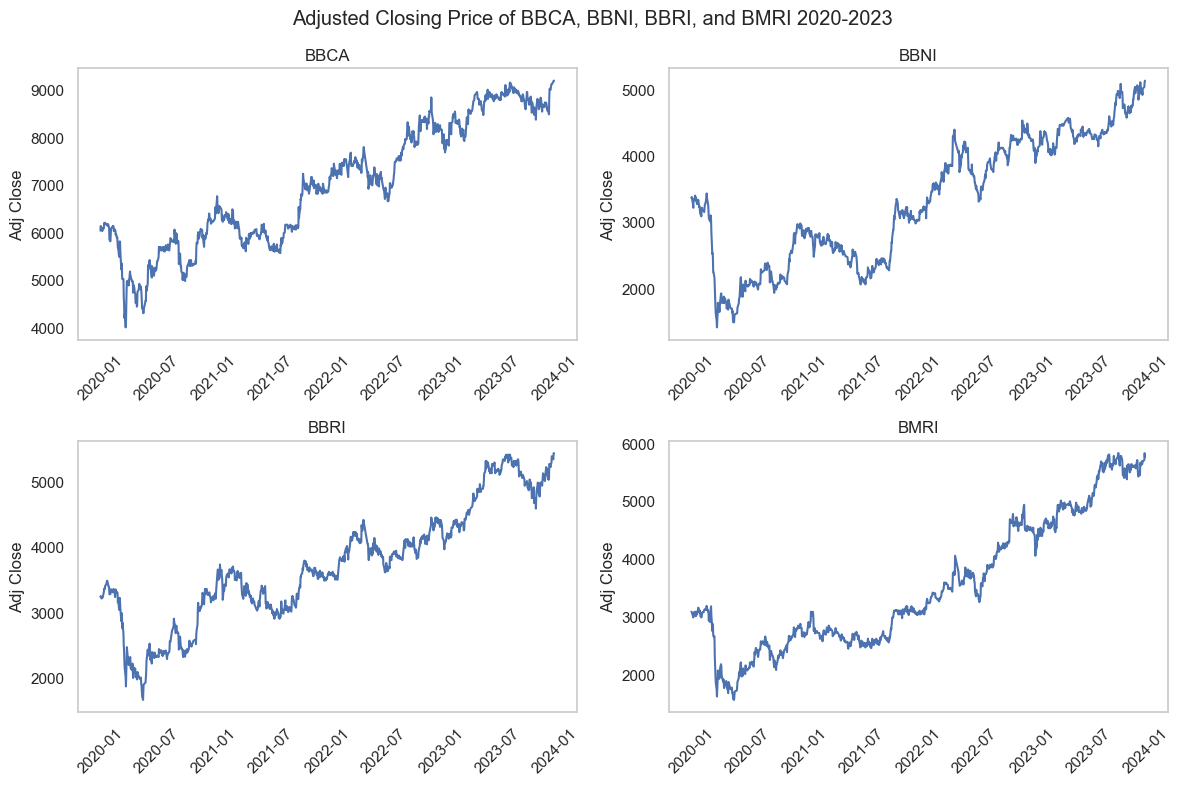
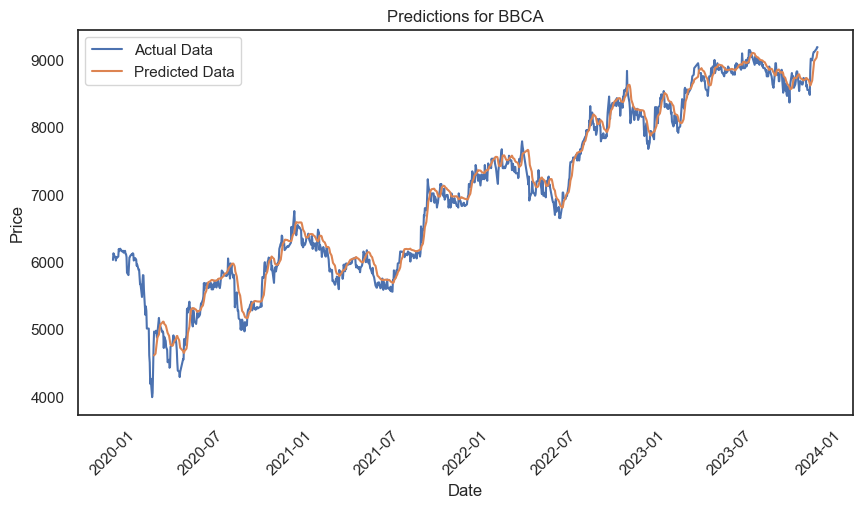
2.1. IDX Banking Stocks Forecast using Long Short-Term Memory (LSTM)

This project demonstrates the development of a stock prediction model for the Indonesian banking sector using the LSTM model. The LSTM model is built with PyTroch with training data taken from the beginning of 2020 to the end of 2023 using yfinance. The training data amounted to 779 and the evaluation data amounted to 195.
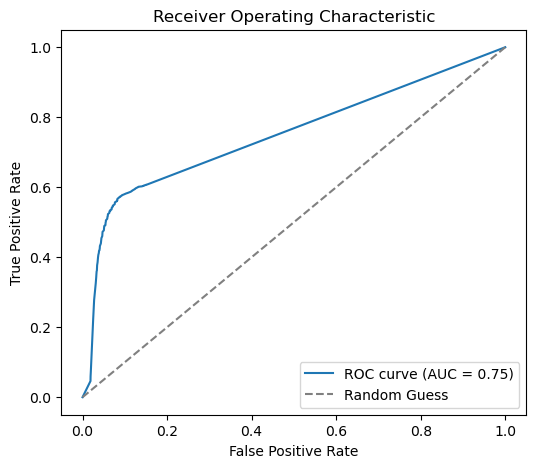
2.2. E-Commerce Transaction Fraud Detection using Machine Learning

This project involves the development and deployment of a classification model to detect fraud in e-commerce transactions based on user transaction data. The best model is Decision Tree Classifier with a precision value of 0.63 and ROC-AUC of 0.75 for the test data. The project was developed by applying a standardized folder structure to facilitate project organization and management, reproducibility, and automation.

3. Web Scraping
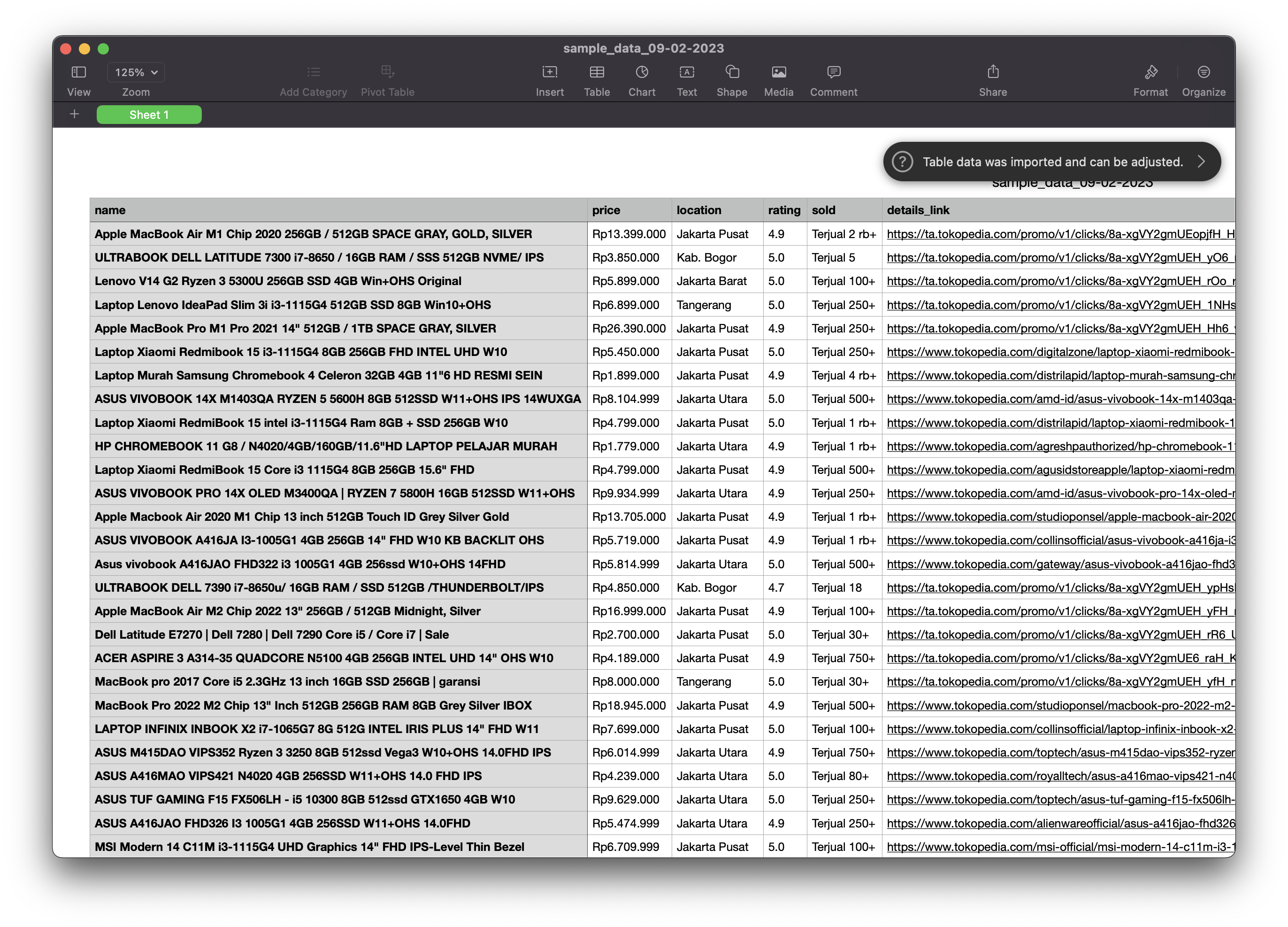
3.1. Tokopedia Scraper


The program aimed to extract product data from the Tokopedia marketplace website based on specified keywords using web scraping techniques. Selenium with JavaScript-enabled selectors was utilized to extract the data due to the dynamic elements on the website. The extracted data included product name, price, location, rating, number of items sold, and details link, which were essential for data analysis and market research. The data was saved in both CSV and JSON formats for further processing and analysis.
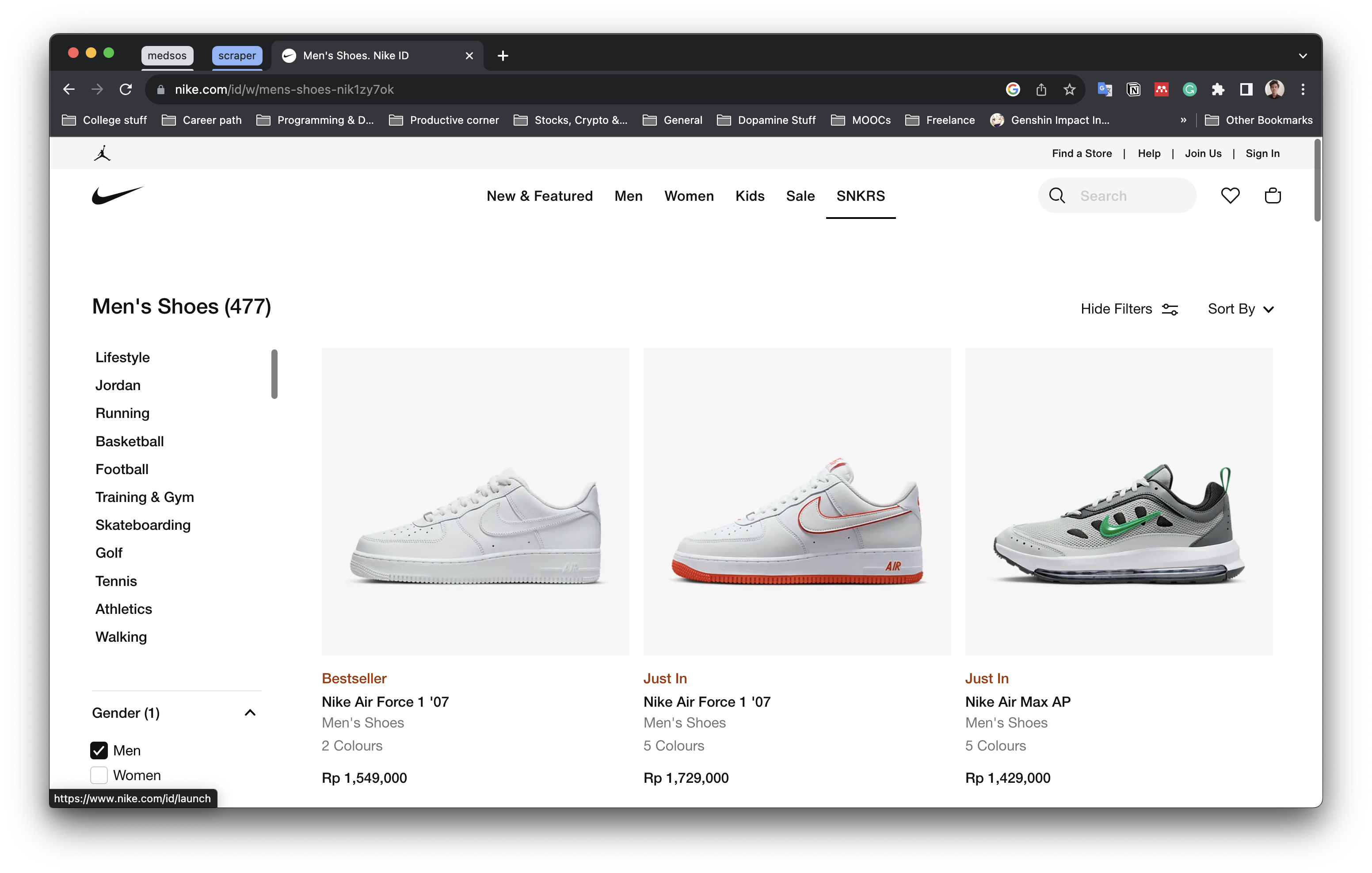
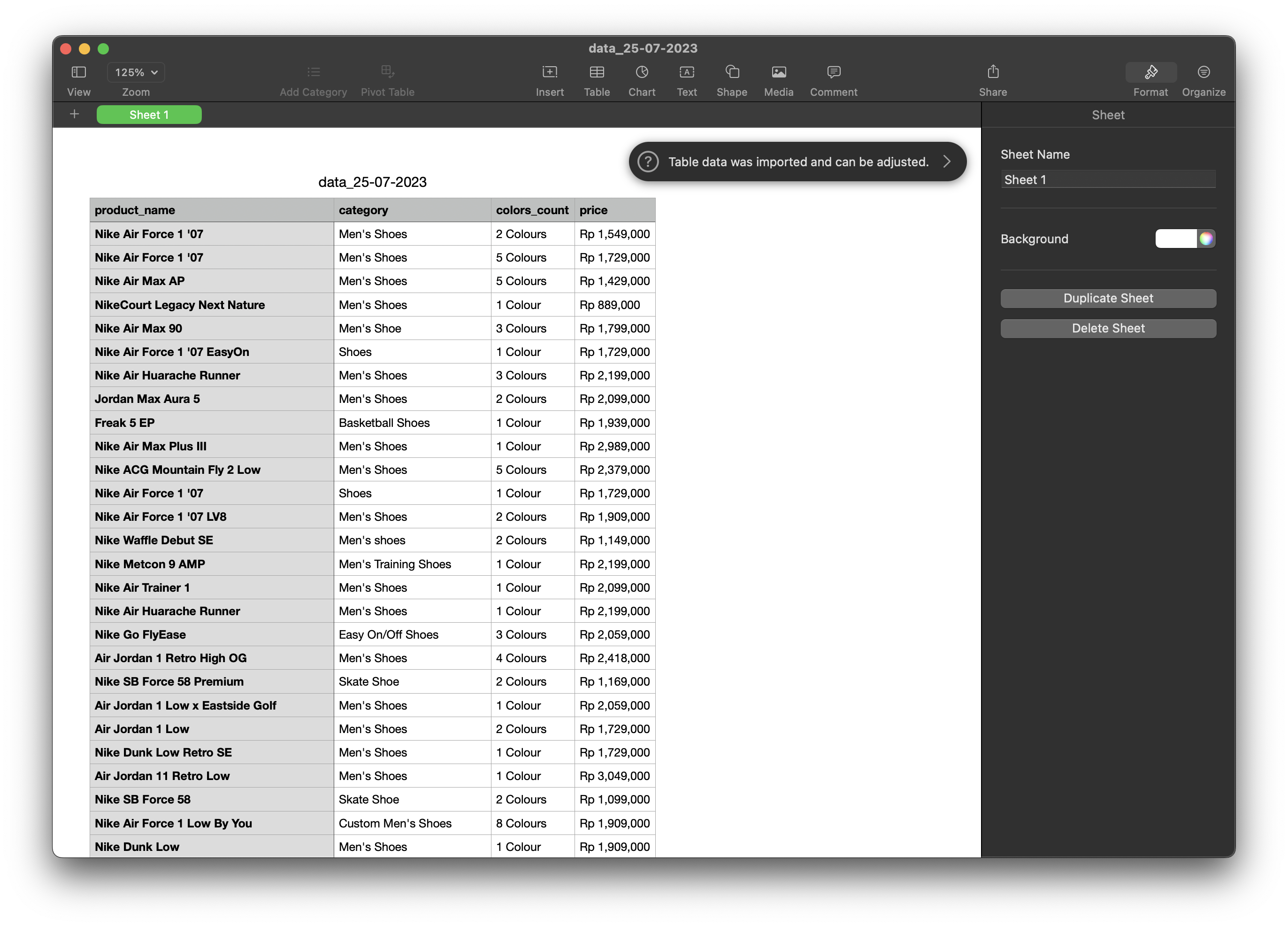
3.2. Nike Scraper

Web Scraper program to extract products data from Nike website using Playwright. Playwright is an open-source Node.js library developed by Microsoft for cross-browser web automation and testing. The data retrieved include product name, category, number of colors, and prices which are then exported into csv and json.
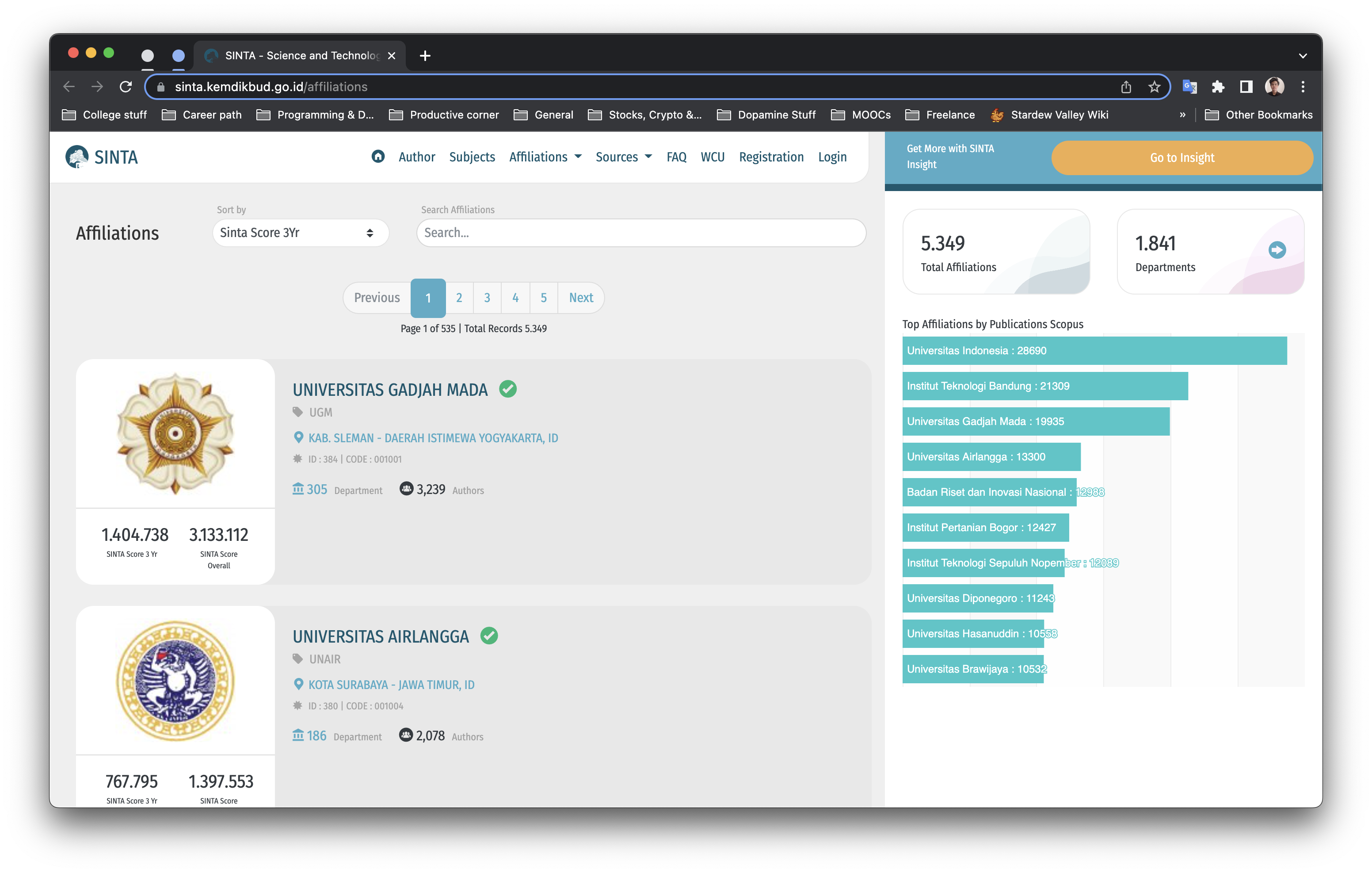
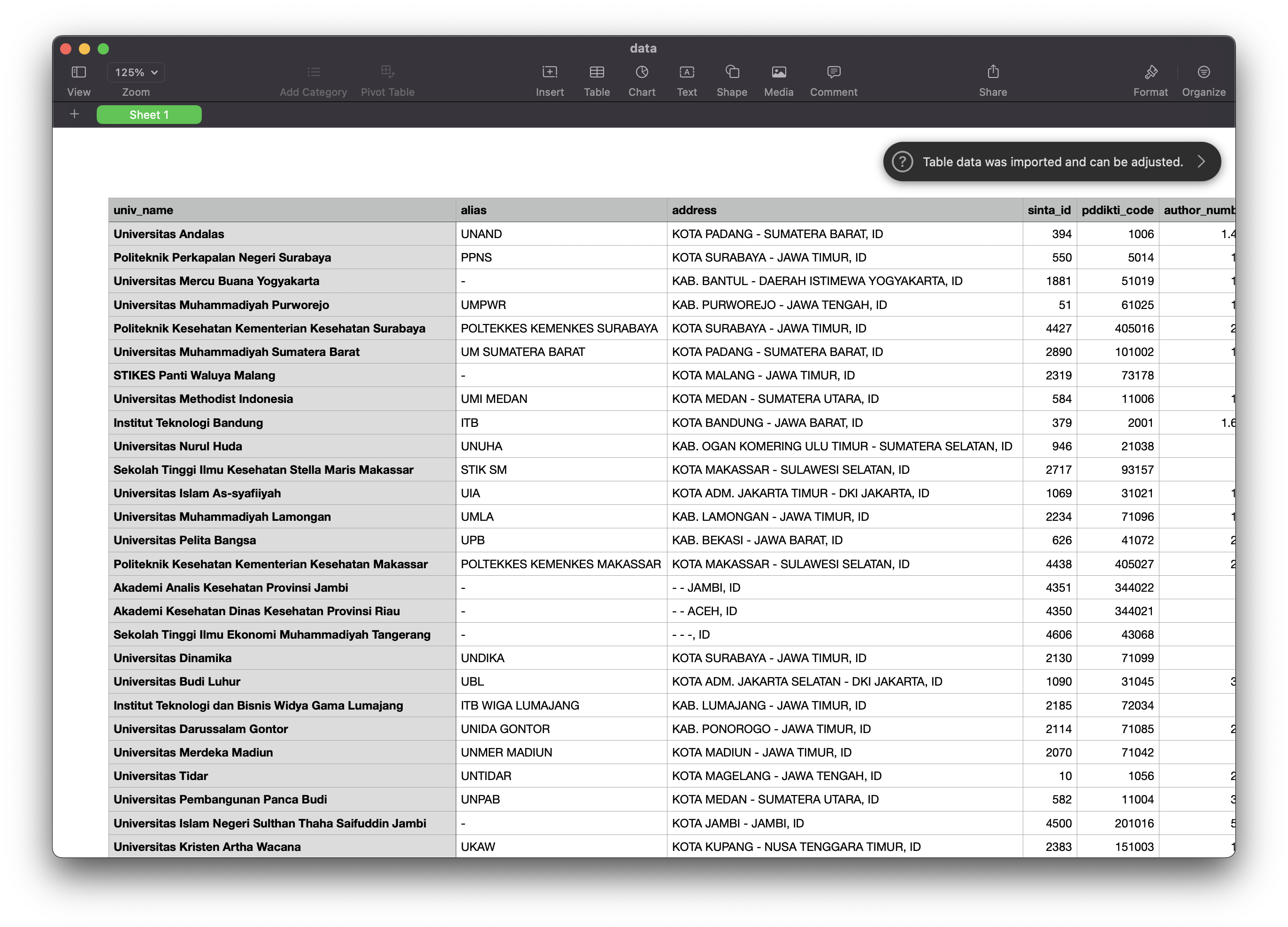
3.3. SINTA Scraper

The program aimed to extract university data and publication scores from the SINTA website using Scrapy. The targeted website is static, and the data is not loaded using JavaScript, which makes Scrapy an appropriate choice due to its efficiency and speed in handling static data on websites. The extracted data included relevant data such as the university's name, location, and publication scores. The data was saved in CSV format for further processing and analysis.
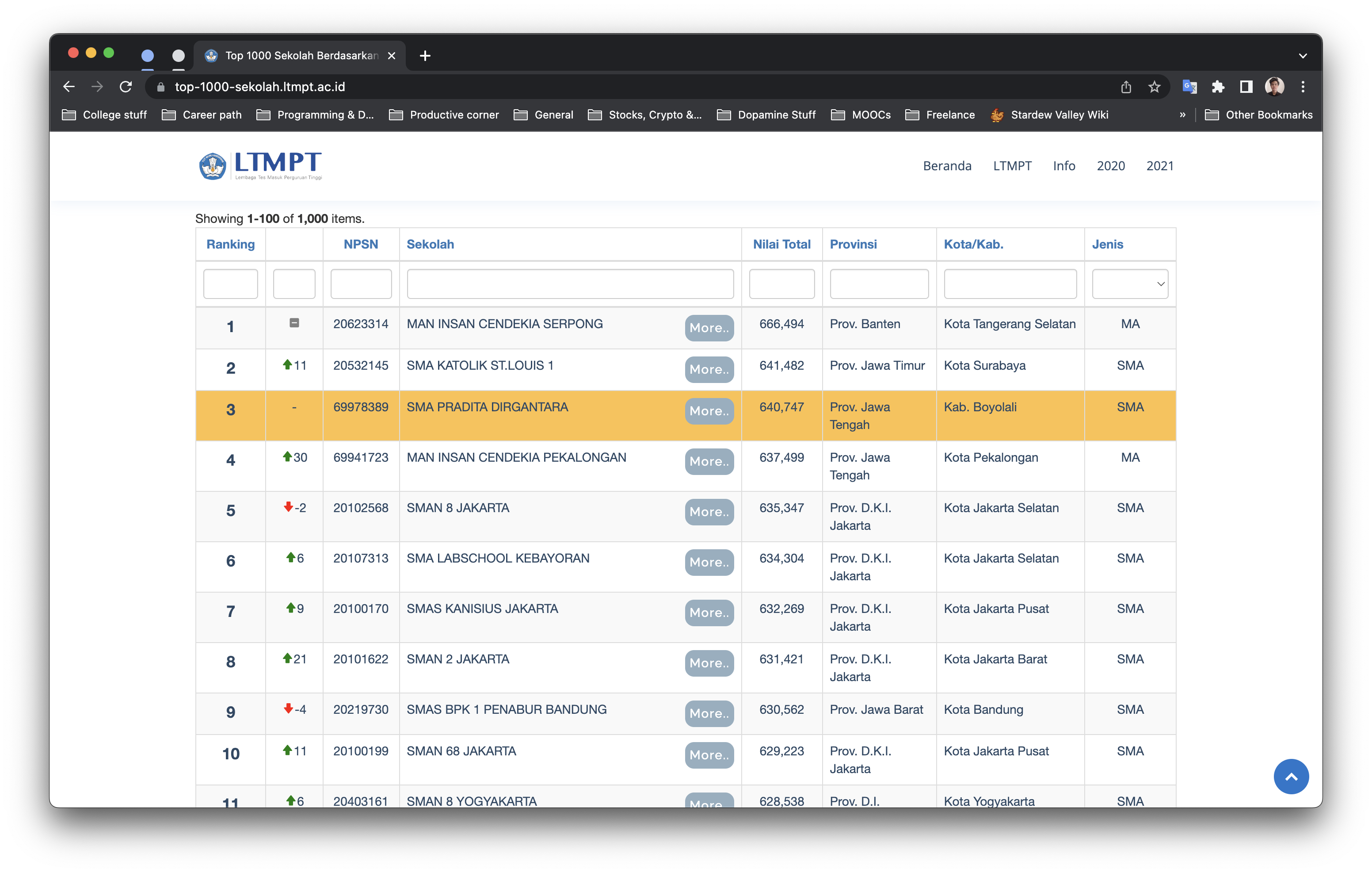
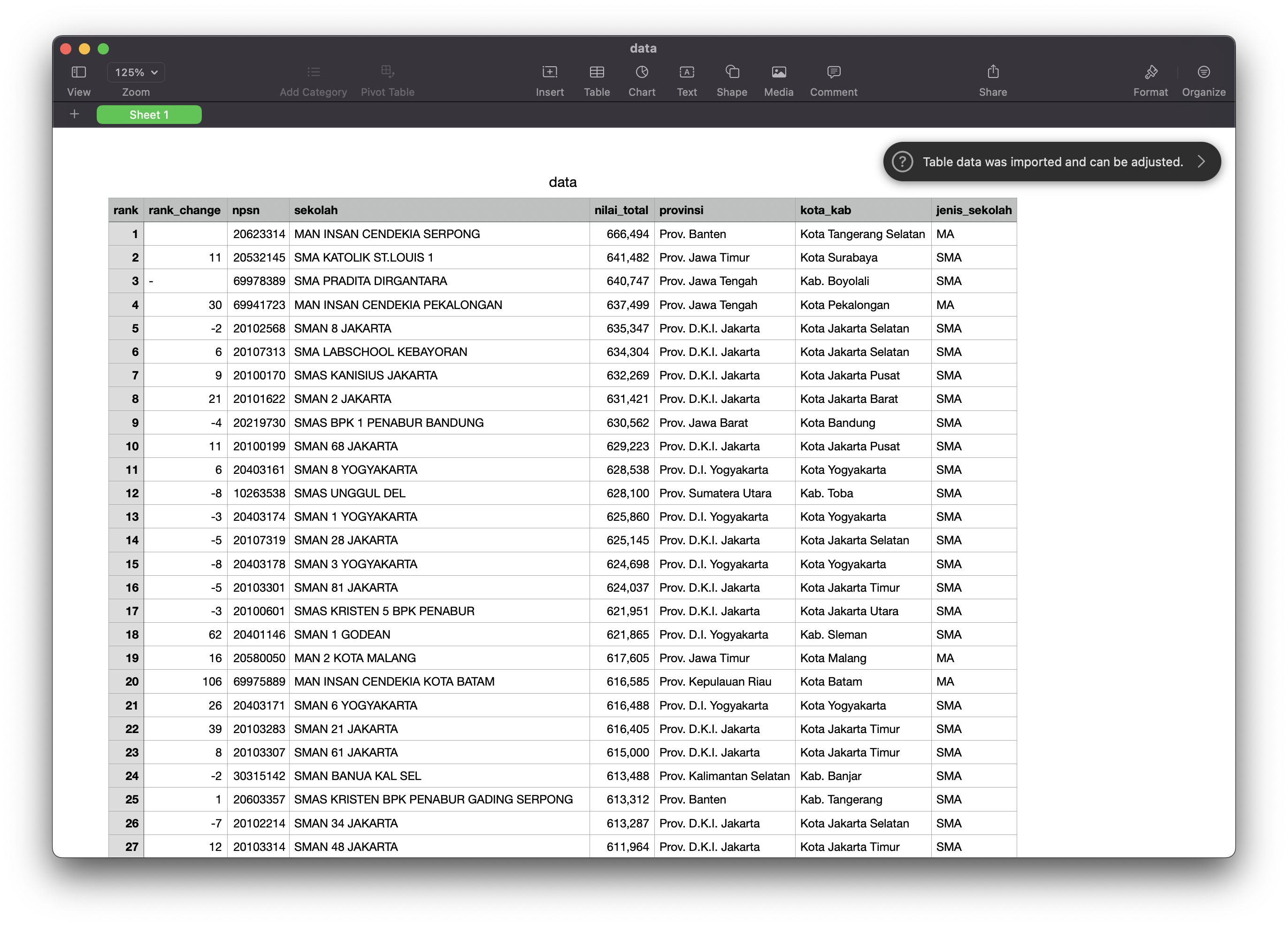
3.4. LTMPT Scraper

The program aimed to extract data on the top 1000 schools based on UTBK scores in 2022 using Scrapy. The targeted website was a static one, and the data was not loaded using JavaScript. Therefore, Scrapy was an appropriate choice due to its efficiency and speed in handling static data on websites. The program extracted relevant data such as the schools' names, locations, UTBK scores, and other relevant information. The extracted data was useful for analyzing and evaluating the schools' academic performance and ranking. The data was saved in CSV format for further processing and analysis.